Spark Native SQL Engine
A Native Engine for Spark SQL with vectorized SIMD optimizations
Introduction
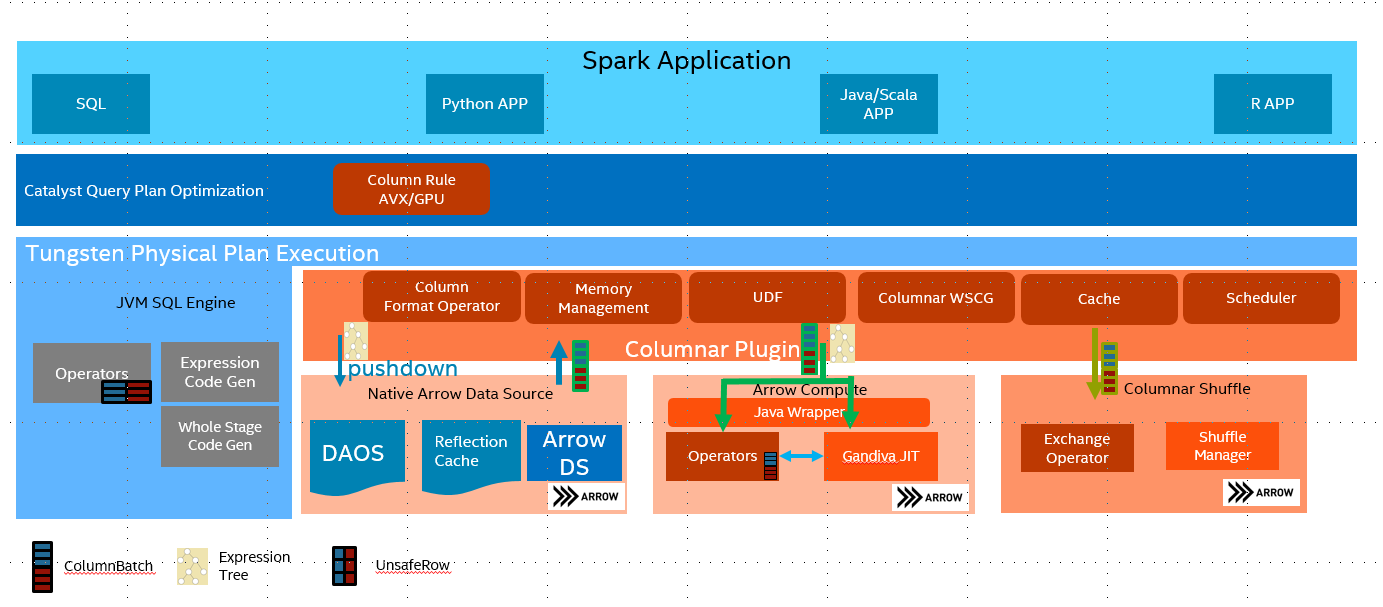
Spark SQL works very well with structured row-based data. It used WholeStageCodeGen to improve the performance by Java JIT code. However Java JIT is usually not working very well on utilizing latest SIMD instructions, especially under complicated queries. Apache Arrow provided CPU-cache friendly columnar in-memory layout, its SIMD optimized kernels and LLVM based SQL engine Gandiva are also very efficient. Native SQL Engine used these technologies and brought better performance to Spark SQL.
Key Features
Apache Arrow formatted intermediate data among Spark operator
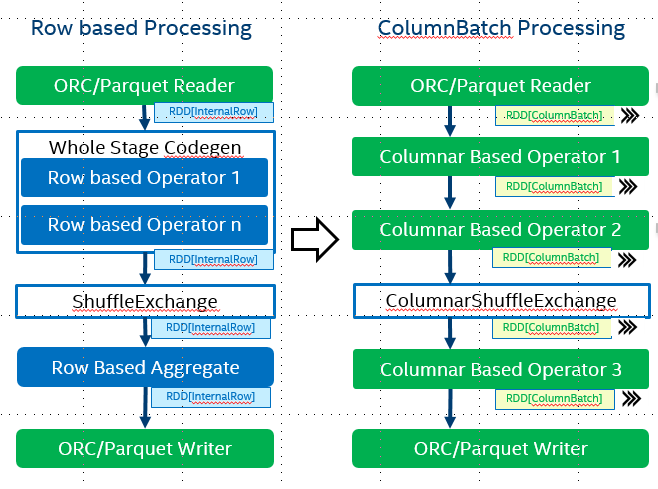
With Spark 27396 its possible to pass a RDD of Columnarbatch to operators. We implemented this API with Arrow columnar format.
Apache Arrow based Native Readers for Parquet and other formats
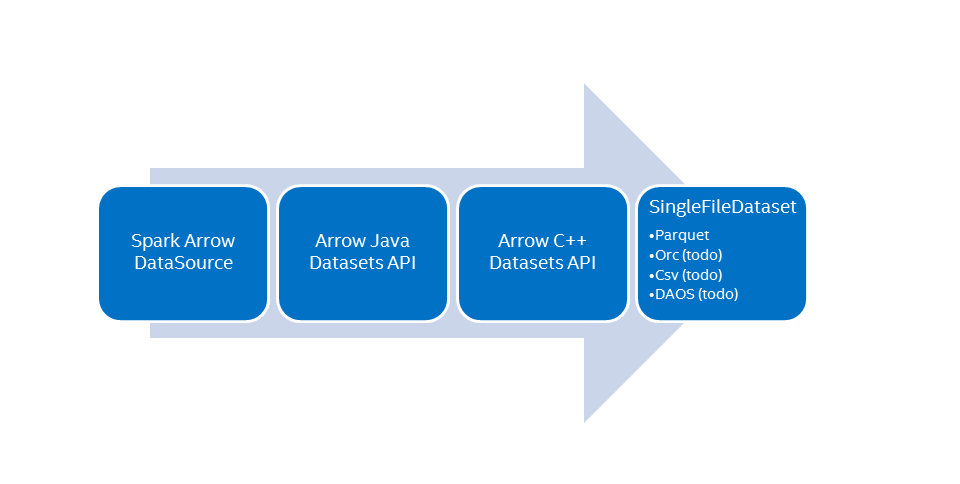
A native parquet reader was developed to speed up the data loading. it's based on Apache Arrow Dataset. For details please check Arrow Data Source
Apache Arrow Compute/Gandiva based operators
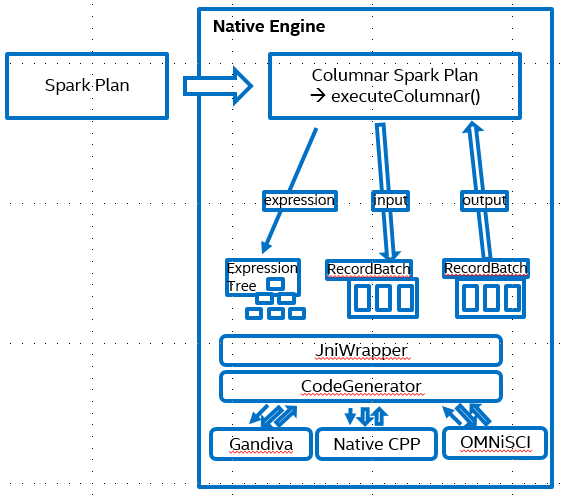
We implemented common operators based on Apache Arrow Compute and Gandiva. The SQL expression was compiled to one expression tree with protobuf and passed to native kernels. The native kernels will then evaluate the these expressions based on the input columnar batch.
Native Columnar Shuffle Operator with efficient compression support
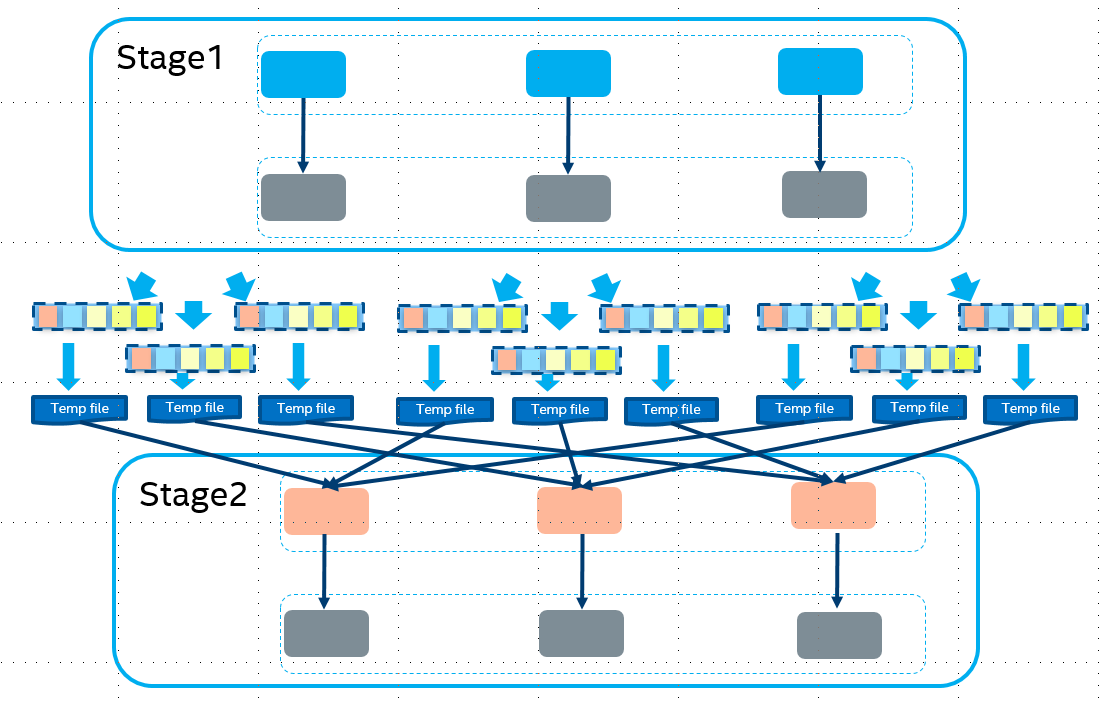
We implemented columnar shuffle to improve the shuffle performance. With the columnar layout we could do very efficient data compression for different data format.
Please check the operator supporting details here
Build the Plugin
Building by Conda
If you already have a working Hadoop Spark Cluster, we provide a Conda package which will automatically install dependencies needed by OAP, you can refer to OAP-Installation-Guide for more information. Once finished OAP-Installation-Guide, you can find built spark-columnar-core-<version>-jar-with-dependencies.jar under $HOME/miniconda2/envs/oapenv/oap_jars.
Then you can just skip below steps and jump to Get Started.
Building by yourself
If you prefer to build from the source code on your hand, please follow below steps to set up your environment.
Prerequisite
There are some requirements before you build the project. Please check the document Prerequisite and make sure you have already installed the software in your system. If you are running a SPARK Cluster, please make sure all the software are installed in every single node.
Installation
Please check the document Installation Guide
Configuration & Testing
Please check the document Configuration Guide
Get started
To enable OAP NativeSQL Engine, the previous built jar spark-columnar-core-<version>-jar-with-dependencies.jar should be added to Spark configuration. We also recommend to use spark-arrow-datasource-standard-<version>-jar-with-dependencies.jar. We will demonstrate an example by using both jar files.
SPARK related options are:
spark.driver.extraClassPath: Set to load jar file to driver.spark.executor.extraClassPath: Set to load jar file to executor.jars: Set to copy jar file to the executors when using yarn cluster mode.spark.executorEnv.ARROW_LIBHDFS3_DIR: Optional if you are using a custom libhdfs3.so.spark.executorEnv.LD_LIBRARY_PATH: Optional if you are using a custom libhdfs3.so.
For Spark Standalone Mode, please set the above value as relative path to the jar file. For Spark Yarn Cluster Mode, please set the above value as absolute path to the jar file.
Example to run Spark Shell with ArrowDataSource jar file
${SPARK_HOME}/bin/spark-shell \
--verbose \
--master yarn \
--driver-memory 10G \
--conf spark.driver.extraClassPath=$PATH_TO_JAR/spark-arrow-datasource-standard-<version>-jar-with-dependencies.jar:$PATH_TO_JAR/spark-columnar-core-<version>-jar-with-dependencies.jar \
--conf spark.executor.extraClassPath=$PATH_TO_JAR/spark-arrow-datasource-standard-<version>-jar-with-dependencies.jar:$PATH_TO_JAR/spark-columnar-core-<version>-jar-with-dependencies.jar \
--conf spark.driver.cores=1 \
--conf spark.executor.instances=12 \
--conf spark.executor.cores=6 \
--conf spark.executor.memory=20G \
--conf spark.memory.offHeap.size=80G \
--conf spark.task.cpus=1 \
--conf spark.locality.wait=0s \
--conf spark.sql.shuffle.partitions=72 \
--conf spark.executorEnv.ARROW_LIBHDFS3_DIR="$PATH_TO_LIBHDFS3_DIR/" \
--conf spark.executorEnv.LD_LIBRARY_PATH="$PATH_TO_LIBHDFS3_DEPENDENCIES_DIR"
--jars $PATH_TO_JAR/spark-arrow-datasource-standard-<version>-jar-with-dependencies.jar,$PATH_TO_JAR/spark-columnar-core-<version>-jar-with-dependencies.jar
Here is one example to verify if native sql engine works, make sure you have TPC-H dataset. We could do a simple projection on one parquet table. For detailed testing scripts, please refer to Solution Guide.
val orders = spark.read.format("arrow").load("hdfs:////user/root/date_tpch_10/orders")
orders.createOrReplaceTempView("orders")
spark.sql("select * from orders where o_orderdate > date '1998-07-26'").show(20000, false)
The result should show up on Spark console and you can check the DAG diagram with some Columnar Processing stage. Native SQL engine still lacks some features, please check out the limitations.
Performance data
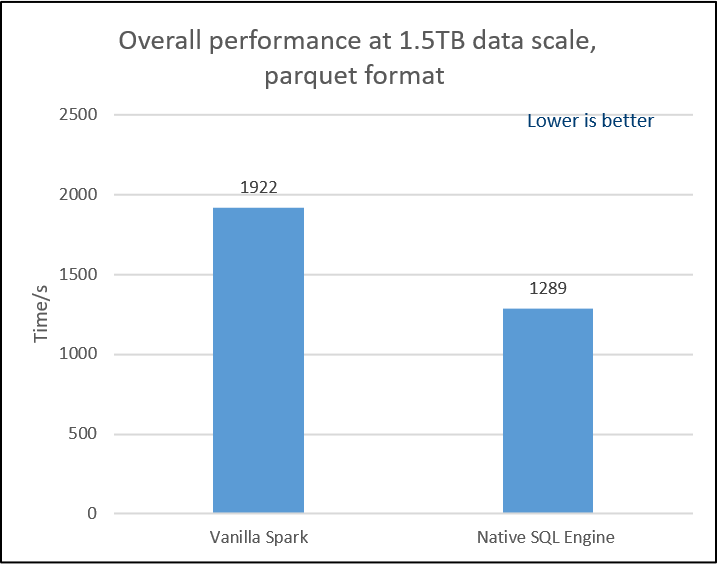
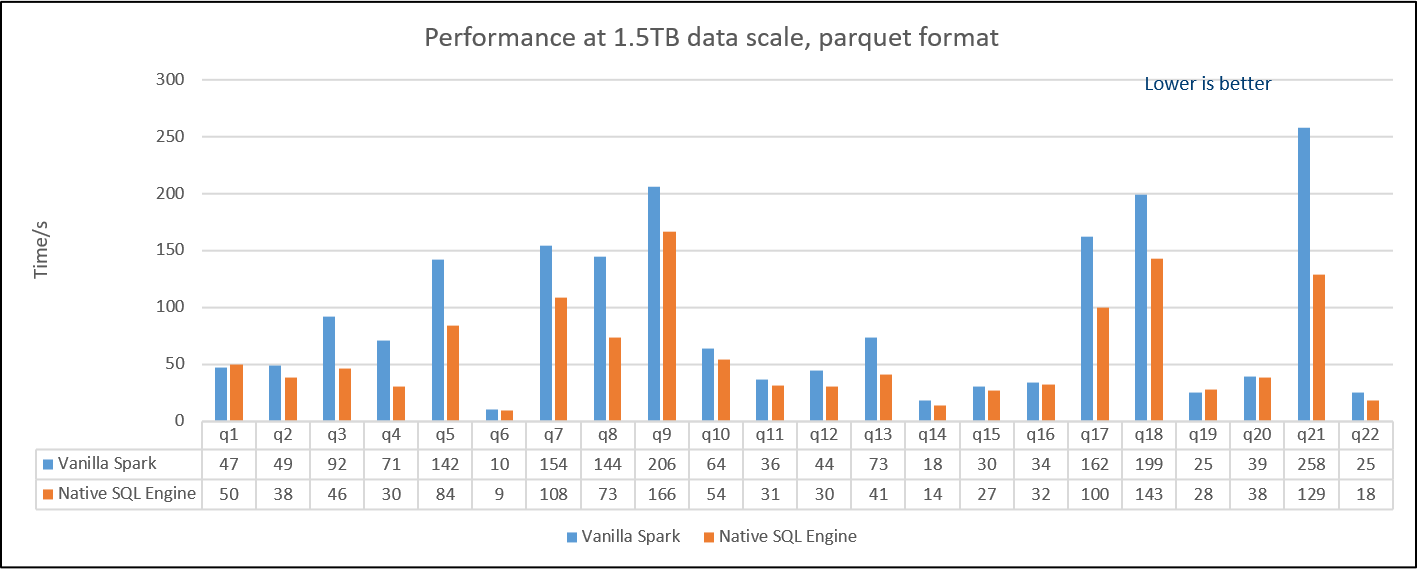
For advanced performance testing, below charts show the results by using two benchmarks: 1. Decision Support Benchmark1 and 2. Decision Support Benchmark2. All the testing environment for Decision Support Benchmark1&2 are using 1 master + 3 workers and Intel(r) Xeon(r) Gold 6252 CPU|384GB memory|NVMe SSD x3 per single node with 1.5TB dataset. * Decision Support Benchmark1 is a query set modified from TPC-H benchmark. We change Decimal to Double since Decimal hasn't been supported in OAP v1.0-Native SQL Engine. Overall, the result shows a 1.49X performance speed up from OAP v1.0-Native SQL Engine comparing to Vanilla SPARK 3.0.0. We also put the detail result by queries, most of queries in Decision Support Benchmark1 can take the advantages from Native SQL Engine. The performance boost ratio may depend on the individual query.
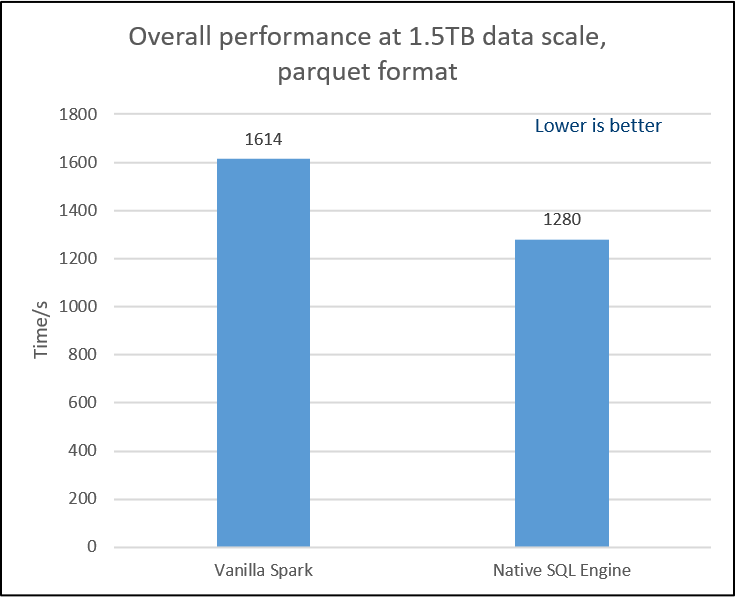
- Decision Support Benchmark2 is a query set modified from TPC-DS benchmark. We change Decimal to Doubel since Decimal hasn't been supported in OAP v1.0-Native SQL Engine. We pick up 10 queries which can be fully supported in OAP v1.0-Native SQL Engine and the result shows a 1.26X performance speed up comparing to Vanilla SPARK 3.0.0.
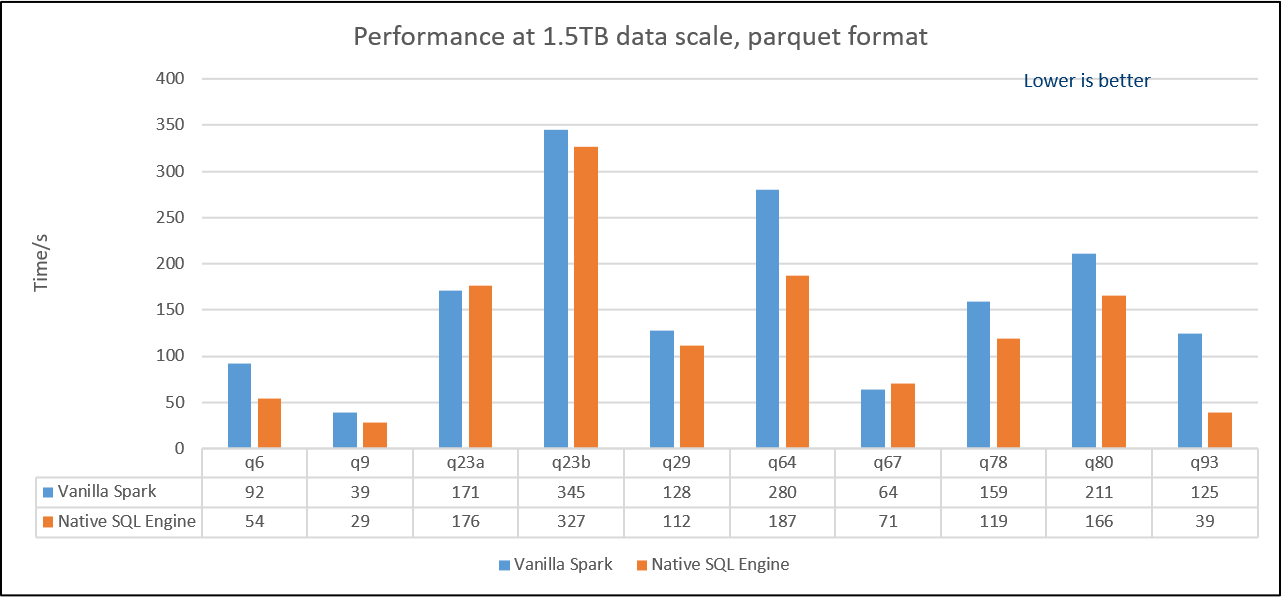
Please notes the performance data is not an official from TPC-H and TPC-DS. The actual performance result may vary by individual workloads. Please try your workloads with native SQL Engine first and check the DAG or log file to see if all the operators can be supported in OAP-Native SQL Engine.
Coding Style
- For Java code, we used google-java-format
- For Scala code, we used Spark Scala Format, please use scalafmt or run ./scalafmt for scala codes format
- For Cpp codes, we used Clang-Format, check on this link google-vim-codefmt for details.
Contact
chendi.xue@intel.com binwei.yang@intel.com